DDIA笔记-第六章-分布式数据-分区
从一个逐步发展的项目来看,数据量和查询量等指标逐步增长, 数据总是先考虑复制,尤其是到了单个节点的某个瓶颈,再考虑分区, 前者为了解决数据可靠和提高吞吐量等, 数据量继续增加,而依然靠复制来增加节点, 那么复制的成本也会增加,导致性价比不高,甚至没有性能提升了。 关于这个,更容易找到的类似的案例是磁盘 RAID 的策略。
- 数据量不大的时候,磁盘直接存储,没有人从这个阶段直接开始搭建 RAID0
- 数据多了,怕丢失数据,RAID1
- 数据已经多到一个盘存不下了,RAID10 = RAID0 + RAID1
- 其他 RAID 方案基本上都是 RAID1 的进阶版本,获得备份功能同时节省硬件设备
分区与复制
分区通常和复制结合使用,最终的拓扑图很难文字讲完,见图
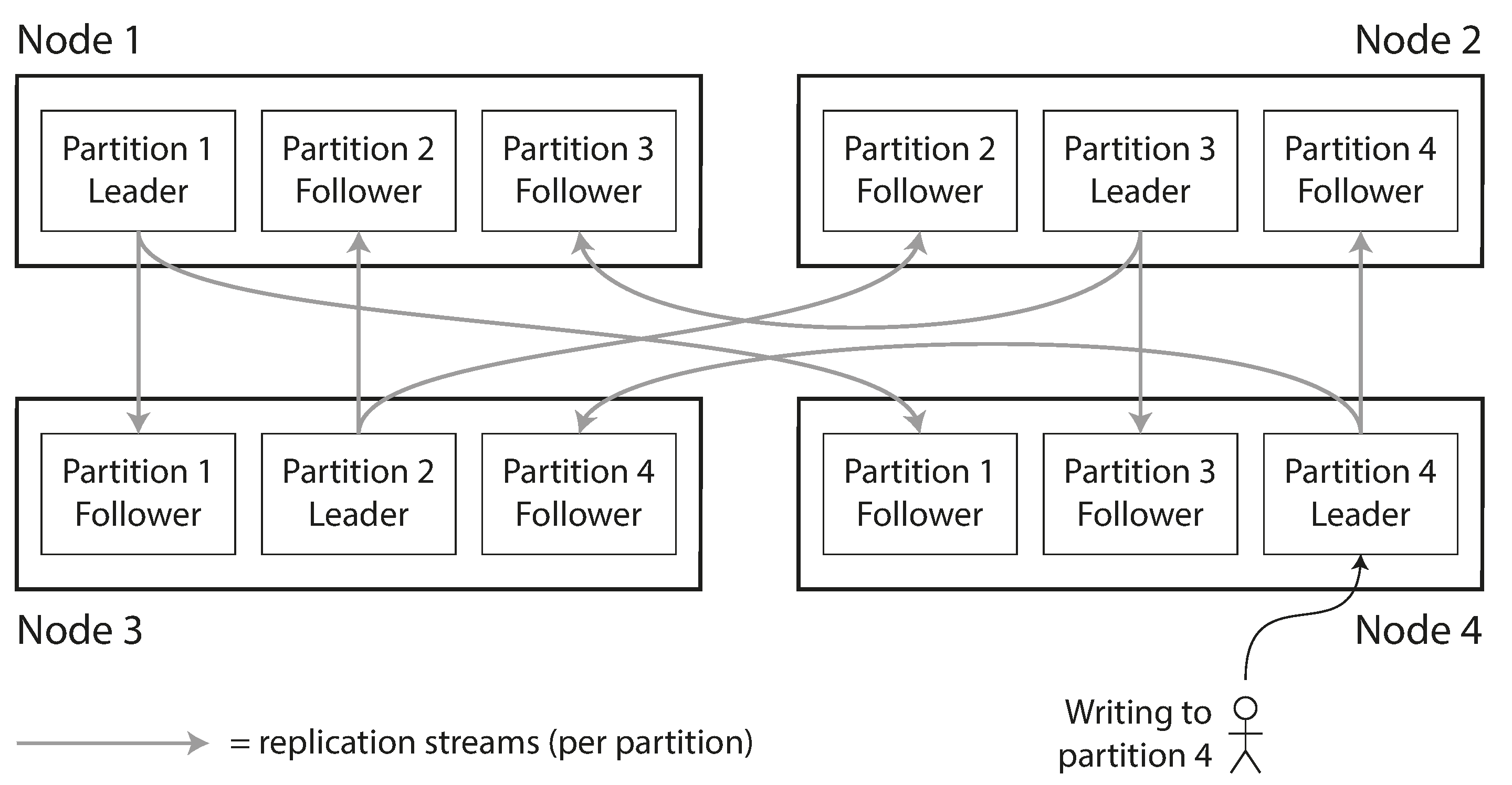
键值数据的分区
如果分区不公平,数据将偏斜(skew),
如果刚好查询也落到这些数据上,这个分区被称为热点(hot spot)
为此我们一般会构造一个主键,按一定规则计算分配的分区。
根据键的范围分区
- 比如按键第一个字母分区
- 当确认分区后,到分区内,可以采用前面第三章提到的存储和检索方法
- 分区的键需要结合业务读写的模式来设计,比如天气
- 用日期作为键值可能对于查询来说很合理,总是连续查询 N 天的数据
- 但是写入可能导致热点,因为今天的数据写入都是同一个分区
根据键的散列分区
- 为了分区更加“公平”,其实就是更加随机,和业务解耦,避免业务逻辑上导致热点
- 键值可以保持“有意义”,然后散列算法获得“随机”值,再以此来分区
- 散列算法并不需要非常复杂,比如 MD5 也可以。但是他们必须有确定性
- 也被称为一致性哈希,但是“一致性”这个命名很多其他概念也用,却完全不在同一维度,尽量避免
- 缺点是明显的,随机之后就不连续了,查询相邻数据,则范围查询变得麻烦
极端情况
- 即使放宽范围查询的能力,采用散列分区,依然不能完全避免问题
- 经典的某明星结婚导致特定键值查询,最后还是造成了热点
- 上述案例的解决方法是
- 特定名人的主键额外拼接一个随机数
- 额外记录这些名人和这个方案必要的其他参数
- 不是所有数据都适合这样做,需要人为挑选,或者根据经验主键形成算法
PS:现在回头看自己做的“磁盘按 uuid 存文件,mysql 按路径记录”的方案
- 文件在磁盘上按散列分区了,而范围查询是由 mysql 提供的
- 磁盘上按散列分区也不是很合理
- 因为 uuid 并没有确定性,反而有用 mysql 记录了 path 和 uuid 对应关系重新建立确定性了
- 对 path 按 md5 或 sha256 会更合理,查询指定路径的文件可以不用先查询一次 mysql
- 主角是磁盘文件,通过散列算法就能以 path 为键读写文件,作为最小系统已经闭环
- mysql 作为辅助,可以看作不同数据结构的从库,配合业务需求,提供更多数据和更多查询方法
- 那么磁盘文件看作主库,mysql 看作从库,有一套复制逻辑,现在确实有这套异步复制逻辑
分区与次级索引
本地索引
基于文档的次级索引进行分区,也被称为 本地索引,
每个分区维护自己的次级索引,只记录自己分区拥有的数据,
显然查询时需要查询每个分区,最后合并结果。
(原文)这种查询分区数据库的方法有时被称为 分散 / 聚集(scatter/gather) ,并且可能会使次级索引上的读取查询相当昂贵。即使并行查询分区,分散 / 聚集也容易导致尾部延迟放大(请参阅 “实践中的百分位点”)。
虽然但是,依然被广泛使用,MongoDB 和 ES 都用了。
举例:汽车按照某个 ID 分区,按颜色/品牌建立了本地索引,当查询红色汽车时,需要分散/聚集。
全局索引
考虑到本地索引的问题,就希望建立一个全局索引作为优化方案,
首先想到分区之外建立一个全局索引,但这违背分区的初衷,
建立在外部某单点或者某特定分区,都会造成瓶颈。
本地索引的问题本质是,对次级索引的查询和其分区规则不匹配,正如上面举的例子。
所以我们应该根据查询的需求来指定分区的规则,
我们把颜色建立全局索引,然后把这个全局索引重新按颜色分区,红色在分区 A,黄色在分区 B。
所谓的查询的需求是我自己的说法,书中指出,这种索引称为 关键词分区(term-partitioned) ,红色/黄色就是关键词。
全局索引使得读取更有效率,避免了分散/收集所有分区,但是写入速度较慢且逻辑复杂,
本来写入只需要操作单个分区,现在是多个。
考虑到索引如何写入,又视乎面临了事务性,除了数据本身的写入,还需要确保每个索引都准确写入了对应分区。
事实上并不会这样做,通常是异步的,没有完美的方案,享受其优势并直接承受风险。有些提供选择配置,有些告知风险。
例如,Amazon DynamoDB 声称在正常情况下,其全局次级索引会在不到一秒的时间内更新,但在基础架构出现故障的情况下可能会有延迟
分区再平衡
其实就是口头上的迁移,
不管要升级 cpu/disk/ram 等,还是硬件故障等等,总是需要迁移,
包括增减节点,都统一讨论,称为再平衡(rebalancing) ,最低要求是:
- 再平衡之后,负载(数据存储,读取和写入请求)应该在集群中的节点之间公平地共享。
- 再平衡发生时,数据库应该继续接受读取和写入。
- 节点之间只移动必须的数据,以便快速再平衡,并减少网络和磁盘 I/O 负载。
反面教材:hash mod N (hash % 10)
在讨论这个话题之前,hash % 10 几乎是最简单的方法,也非常好理解。
但是想象一下,当你有 10 个节点时%10,但需要扩容到 11 个节点时会发生什么,
123456%10=6 号分区,123456%11=3 号分区,如此类推你会发现大部分数据都需要被迁移。
这个情况在分表中已经显露出来了,分表是项目演变过程中更早遇到的,
如果利用 userID%4 作为分表规则,那么业务量继续增长,当你希望增加分表数量时,需要迁移的数据量是很大的。
另外 userID%4 作为某个服务子进程分发规则是可行的,
有时候考虑到后端服务是无状态的,前端是异步请求的,而实际业务又需要有一定顺序,
可能存在一组服务,服务本身是单线程的,保证了业务是顺序执行,然后用 userID 做规则分发请求到特定服务进程,
这样能维持,前后端大部分框架不变,业务代码不需要关心太多,的情况下,
由后端这个“分发”实现了某个用户的操作串行,
如果要服务组增加节点,则 userID%5,只需要“分发器”重新加载时,
保证某个 userID 没有未完成的业务即可,代码里做点小设计即可实现。
其重点在于现代大部分后端服务都是“无状态”的。
固定数量的分区
基于上面的问题,我们可以一开始就固定设置足够多的分区,在数据库第一次建立就确定,之后不会改变,
这样我们规避了重新分区导致数据迁移的问题,
那增减节点的应对方式是,直接迁移整个分区。
现在我们会看到一个新景象:一个节点并不只有一个分区。
在此之前,虽然我们也会了解到一个物理机上可能运行着多个实例的情况,但现在我们有了足够的理由这样做。
其实还有其他,比如更好利用 CPU,只是一个可以一起思考的类比现象而已。
所以这个方案指的是,我们有 20 个分区,现在存放在 4 个节点,每个节点存放了 5 个分区。
需要增加到 5 个节点时,我们从现在的 4 个节点中各抽出一个分区放到新节点。
在新节点可用之前,我们保持原来的分区可以读写,新节点也会“复制”新的读写,
直到新节点准备好了,调整分区映射关系,最后释放原来节点上的已经迁移了的分区。
因为如果要重新迁移分区里面的数据是困难的,所以我们一开始就要确定分区的数量。
这就需要我们预估数据的规模,“恰到好处”需要一定的经验来判断。
设置小了,后期一个分区数据量太大导致性能下降,
设置大了,前期数据量不大,但是被节点之间的管理逻辑拖住了性能。
动态分区
首先这是基于键范围分区的。
可以配置分区超过一定大小时,比如大于 10GB,分成两个分区,
而删除了数据,导致数据量变小时,合并分区,
这样能在不同数据规模时都能得到比较好的性能。
为了避免一开始数据量很小时,单个节点承担所有压力,所以一般支持预分割,让分区不是从一个开始。
插入的个人心得
到这里需要注意,“动态分区”已经不能简单的和“固定数量的分区”对比,
因为他们前提条件已经不同,简单举例是
- 一种是基于直接用自增 ID 来分区,用动态分区来应对数据量的增长
- 一种是基于散列值来分区,需要一开始预估好数据规模,也从一开始就能比较“公平”的分配负载
所以其实“固定数量的分区”解决了“取模分区”需要迁移很多数据的问题,
而这里的拆分/合并分区也需要迁移很多数据,然而并没有很直接的解决方案。
有很多方案都是组合拳,要深刻理解是在“什么前提”下解决“什么问题”,
同时可能带来“新的问题”或重新暴露“别的方案已经解决了的问题”。
并不是说动态分区就不能用在散列分区上,只是这样没有足够的好处,
根据经验,最后沿用下来的方案,真实的解决了某些需求场景。
按节点比例分区
同样基于键范围分区的。
比起动态分区,更稳定的方案可以是:每个节点固定数量的分区。
当你增加节点时,原来节点中分区里的数据量将减少。
这里已经到了非常特定的前提下了,平时用的数据库也很少这种设计,原文也是简单带过了。
运维:手动还是自动再平衡
即使提供了自动再平衡的功能,但这也是一个危险的过程,反正有人参与是一件好事。
(原文)这种自动化与自动故障检测相结合可能十分危险。例如,假设一个节点过载,并且对请求的响应暂时很慢。其他节点得出结论:过载的节点已经死亡,并自动重新平衡集群,使负载离开它。这会对已经超负荷的节点,其他节点和网络造成额外的负载,从而使情况变得更糟,并可能导致级联失败。
请求路由
数据分区之后,客户端的请求需要直到访问哪个分区,可以归纳到服务发现(service discovery)
有很多已经开源的项目来处理服务发现,可以概括为几种方案:
- 谁都不知道规则,允许客户联系任何节点,节点会自己循环传递这个请求,直到节点刚好拥有查询的分区
- 路由层知道规则,请求都发送到路由层,计算出对应分区后,转发请求,只转发,不处理。
- 客户端知道规则,客户端自己能计算出对应的分区,直接访问
执行并行查询
上面讨论的都是简单查询,而大规模并行处理(MPP, Massively parallel processing) 后面再专门讨论
1